MobileDev-Bench: A Benchmark for Issue Resolution in Mobile Application Development
TL;DR: MobileDev-Bench evaluates whether LLM coding agents can resolve real mobile app issues across Android, Flutter, and React Native. On 407 verified tasks, frontier models resolve only 3.23%-4.23% under automated retrieval.
Key Takeaways
- Mobile-specific gap: Current issue-resolution benchmarks focus mainly on library-style repositories; MobileDev-Bench targets app-level mobile systems with framework build constraints, UI/resource artifacts, and platform APIs.
- Patch complexity: Fixes modify 12.9 files and 334.6 lines on average, and 41% of instances require coordinated changes across multiple artifact types.
- Coordination bottleneck: Single-file tasks reach 12.7%-15.5% automated resolution, but tasks requiring 6 or more files drop to 0% across all evaluated models.
MobileDev-Bench Leaderboard
The leaderboard summarizes end-to-end issue resolution. Use the toggles to switch retrieval settings and click table headers to sort.
Tracks
- Automated Retrieval: the agent must retrieve context and generate a patch.
- Oracle Retrieval: the agent receives the ground-truth files, isolating patch generation.
| # | Model | Resolved | Rate | Single File | Multi-Artifact |
|---|
Values are resolution rates on 407 verified tasks. Single-file and multi-artifact columns show category-specific rates.
What is MobileDev-Bench?
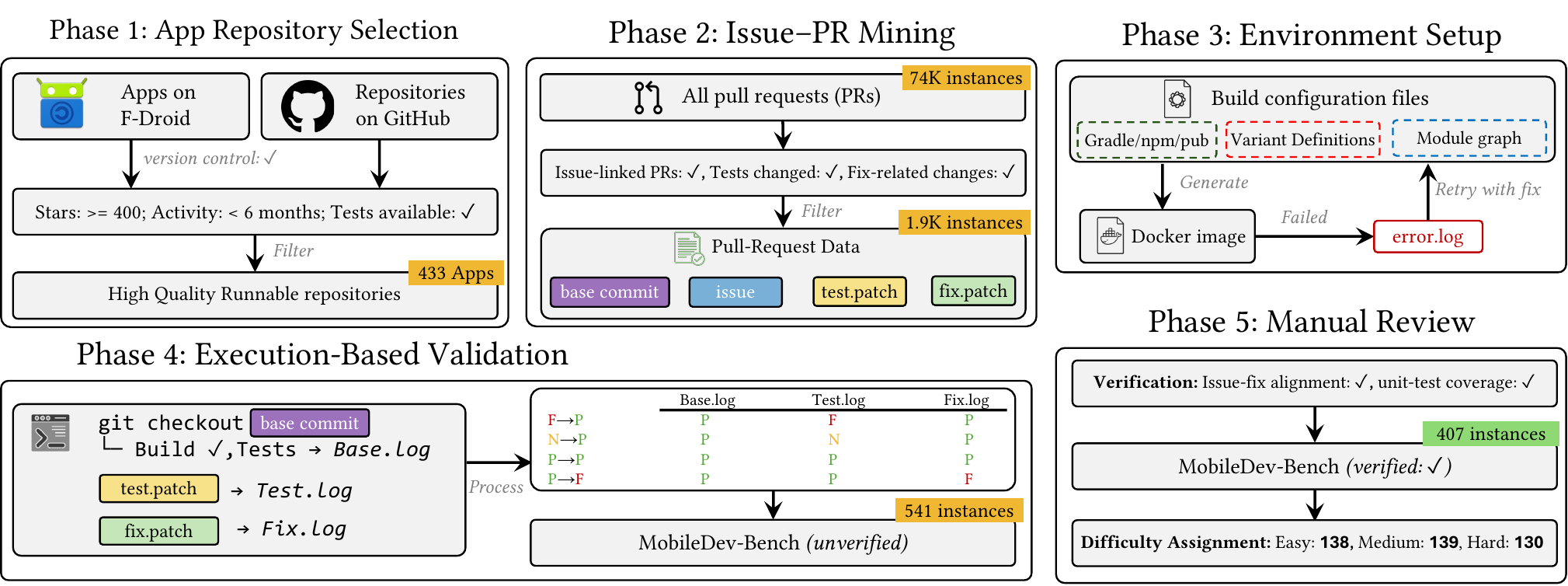
MobileDev-Bench instances are mined from issue-linked pull requests in production mobile applications. Each task includes a base commit, issue statement, fix patch, test patch, and reproducible container environment. Validation executes mobile builds and tests to verify whether a generated patch resolves the issue.
MobileDev-Bench at a Glance
How are tasks evaluated?
Execution validation: Generated patches are applied to the base repository and checked against executable test patches inside mobile build environments.
Resolution rate: A task is resolved only when the generated patch passes the validation tests for the issue.
Retrieval metrics: File-level recall, precision, and F1 quantify whether agents identify the files that must be modified.
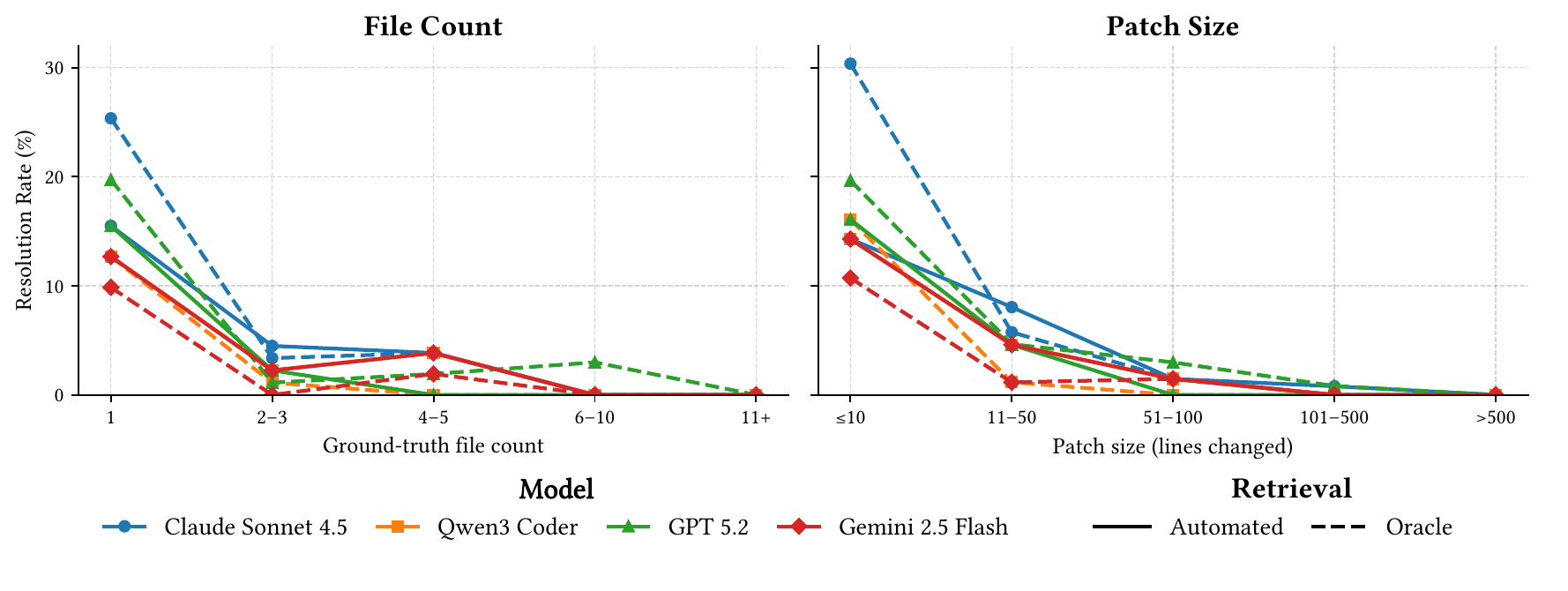
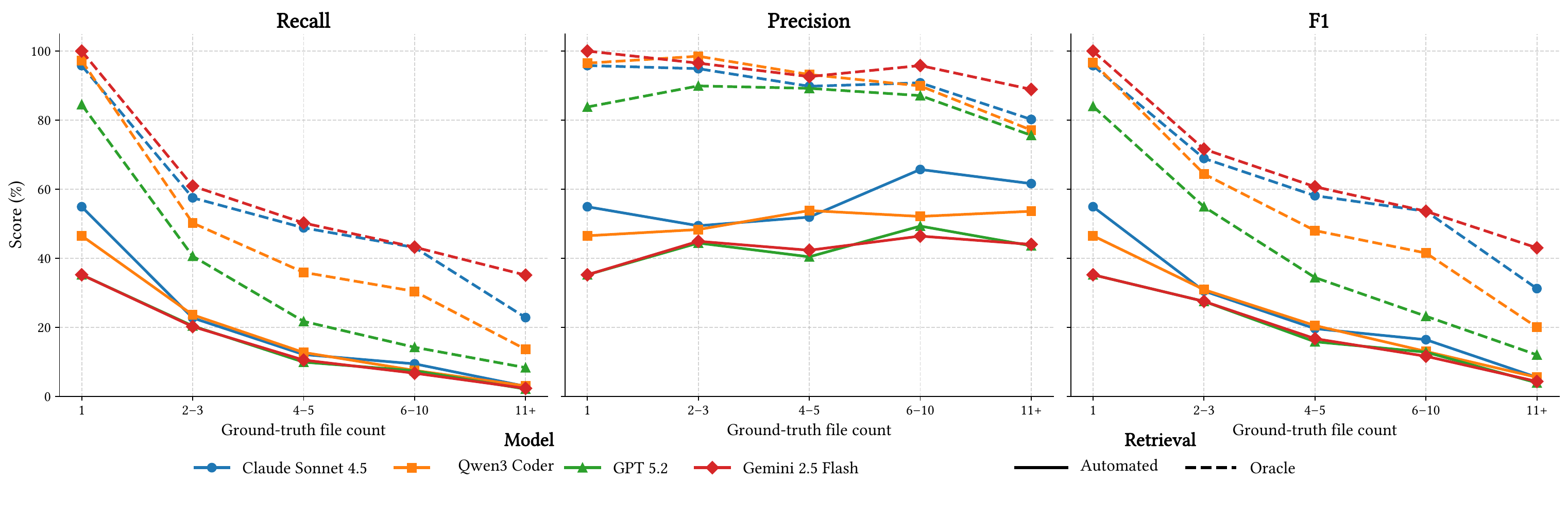
How can I evaluate my model?
To run your own agent on MobileDev-Bench and evaluate its performance, please consult the repository README.
Citation
@misc{fakorede2026mobiledevbench,
title={MobileDev-Bench: A Benchmark for Issue Resolution in Mobile Application Development},
author={Moshood A. Fakorede and Krishna Upadhyay and A. B. Siddique and Umar Farooq},
year={2026},
eprint={2603.24946},
archivePrefix={arXiv},
primaryClass={cs.SE},
url={https://arxiv.org/abs/2603.24946},
}